第 7 章:Kubernetes 網路原理
kubernetes 網路模型
- 每個 pod 有獨立的 IP address
- 每個 pod 可以連線到其他 pod
- 所有容器都可以不用 NAT 的方式下同別的容器通信
- 所有節點都可以不用 NAT 的方式下同所有容器通信
Docker 網路模型
- network namespace
- veth
- iptables/betfilter
- bridge
- route
Docker 的網路實現
- host
- container
- none
- bridge
kubernetes 都只使用 bridge
扁平網絡 Flannel
如果你安裝了擁有三個節點的 Kubernetes 集群,節點的狀態如下所述。
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node1 Ready <none> 2d v1.9.1 <none> CentOS Linux 7 (Core) 3.10.0-693.11.6.el7.x86_64 docker://1.12.6
node2 Ready <none> 2d v1.9.1 <none> CentOS Linux 7 (Core) 3.10.0-693.11.6.el7.x86_64 docker://1.12.6
node3 Ready <none> 2d v1.9.1 <none> CentOS Linux 7 (Core) 3.10.0-693.11.6.el7.x86_64 docker://1.12.6
當前 Kubernetes 集群中運行的所有 Pod 信息
kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
kube-system coredns-5984fb8cbb-sjqv9 1/1 Running 0 1h 172.33.68.2 node1
kube-system coredns-5984fb8cbb-tkfrc 1/1 Running 1 1h 172.33.96.3 node3
kube-system heapster-v1.5.0-684c7f9488-z6sdz 4/4 Running 0 1h 172.33.31.3 node2
kube-system kubernetes-dashboard-6b66b8b96c-mnm2c 1/1 Running 0 1h 172.33.31.2 node2
kube-system monitoring-influxdb-grafana-v4-54b7854697-tw9cd 2/2 Running 2 1h 172.33.96.2 node3
當前 etcd 中的注冊的宿主機的 pod 地址網段信息:
etcdctl ls /kube-centos/network/subnets
/kube-centos/network/subnets/172.33.68.0-24
/kube-centos/network/subnets/172.33.31.0-24
/kube-centos/network/subnets/172.33.96.0-24
而每個 node 上的 Pod 子網是根據我們在安裝 flannel 時配置來劃分的,在 etcd 中查看該配置:
etcdctl get /kube-centos/network/config
{"Network":"172.33.0.0/16","SubnetLen":24,"Backend":{"Type":"host-gw"}}
我們知道 Kubernetes 集群內部存在三類 IP,分別是:
- Node IP:宿主機的 IP 地址
- Pod IP:使用網絡插件創建的 IP(如 flannel),使跨主機的 Pod 可以互通
- Cluster IP:虛擬 IP,通過 iptables 規則訪問服務
在安裝 node 節點的時候,節點上的進程是按照 flannel -> docker -> kubelet -> kube-proxy 的順序啟動的,我們下面也會按照該順序來講解,flannel 的網絡劃分和如何與 docker 交互,如何通過 iptables 訪問 service。
Flannel
Flannel 是作為一個二進制文件的方式部署在每個 node 上,主要實現兩個功能:
為每個 node 分配 subnet,容器將自動從該子網中獲取 IP 地址 當有 node 加入到網絡中時,為每個 node 增加路由配置 下面是使用 host-gw backend 的 flannel 網絡架構圖:
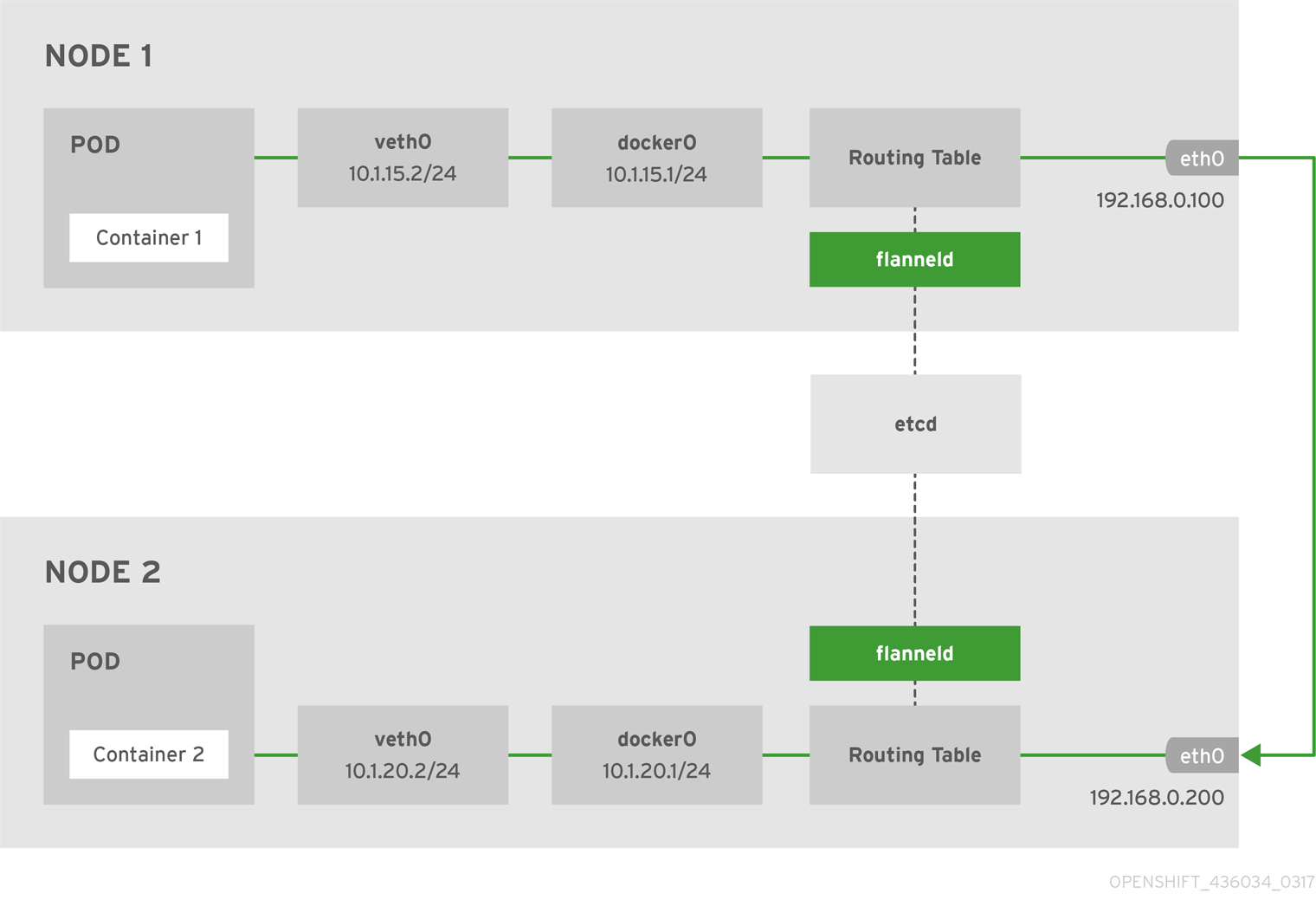
注意:以上 IP 非本示例中的 IP,但是不影響讀者理解。
Node1 上的 flannel 配置如下:
cat /usr/lib/systemd/system/flanneld.service
[Unit]
Description=Flanneld overlay address etcd agent
After=network.target
After=network-online.target
Wants=network-online.target
After=etcd.service
Before=docker.service
[Service]
Type=notify
EnvironmentFile=/etc/sysconfig/flanneld
EnvironmentFile=-/etc/sysconfig/docker-network
ExecStart=/usr/bin/flanneld-start $FLANNEL_OPTIONS
ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker
Restart=on-failure
[Install]
WantedBy=multi-user.target
RequiredBy=docker.service
其中有兩個環境變量文件的配置如下:
cat /etc/sysconfig/flanneld
# Flanneld configuration options
FLANNEL_ETCD_ENDPOINTS="http://172.17.8.101:2379"
FLANNEL_ETCD_PREFIX="/kube-centos/network"
FLANNEL_OPTIONS="-iface=eth2"
上面的配置文件僅供 flanneld 使用。
cat /etc/sysconfig/docker-network
# /etc/sysconfig/docker-network
DOCKER_NETWORK_OPTIONS=
還有一個ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker,其中的/usr/libexec/flannel/mk-docker-opts.sh 腳本是在 flanneld 啟動後運行,將會生成兩個環境變量配置文件:
/run/flannel/docker
/run/flannel/subnet.env
我們再來看下 /run/flannel/docker 的配置。
cat /run/flannel/docker
DOCKER_OPT_BIP="--bip=172.33.68.1/24"
DOCKER_OPT_IPMASQ="--ip-masq=true"
DOCKER_OPT_MTU="--mtu=1500"
DOCKER_NETWORK_OPTIONS="--bip=172.33.68.1/24 --ip-masq=true --mtu=1500"
如果你使用systemctl 命令先啟動 flannel 後啟動 docker 的話,docker 將會讀取以上環境變量。
/run/flannel/subnet.env 的配置
cat /run/flannel/subnet.env
FLANNEL_NETWORK=172.33.0.0/16
FLANNEL_SUBNET=172.33.68.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=false
以上環境變量是 flannel 向 etcd 中�注冊的。
Docker Node1 的 docker 配置如下:
cat /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=http://docs.docker.com
After=network.target rhel-push-plugin.socket registries.service
Wants=docker-storage-setup.service
Requires=docker-cleanup.timer
[Service]
Type=notify
NotifyAccess=all
EnvironmentFile=-/run/containers/registries.conf
EnvironmentFile=-/etc/sysconfig/docker
EnvironmentFile=-/etc/sysconfig/docker-storage
EnvironmentFile=-/etc/sysconfig/docker-network
Environment=GOTRACEBACK=crash
Environment=DOCKER_HTTP_HOST_COMPAT=1
Environment=PATH=/usr/libexec/docker:/usr/bin:/usr/sbin
ExecStart=/usr/bin/dockerd-current \
--add-runtime docker-runc=/usr/libexec/docker/docker-runc-current \
--default-runtime=docker-runc \
--exec-opt native.cgroupdriver=systemd \
--userland-proxy-path=/usr/libexec/docker/docker-proxy-current \
$OPTIONS \
$DOCKER_STORAGE_OPTIONS \
$DOCKER_NETWORK_OPTIONS \
$ADD_REGISTRY \
$BLOCK_REGISTRY \
$INSECURE_REGISTRY\
$REGISTRIES
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=1048576
LimitNPROC=1048576
LimitCORE=infinity
TimeoutStartSec=0
Restart=on-abnormal
MountFlags=slave
KillMode=process
[Install]
WantedBy=multi-user.target
查看 Node1 上的 docker 啟動參數:
systemctl status -l docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/docker.service.d
└─flannel.conf
Active: active (running) since Fri 2018-02-02 22:52:43 CST; 2h 28min ago
Docs: http://docs.docker.com
Main PID: 4334 (dockerd-current)
CGroup: /system.slice/docker.service
‣ 4334 /usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtime=docker-runc --exec-opt native.cgroupdriver=systemd --userland-proxy-path=/usr/libexec/docker/docker-proxy-current --selinux-enabled --log-driver=journald --signature-verification=false --bip=172.33.68.1/24 --ip-masq=true --mtu=1500
我們可以看到在 docker 在啟動時有如下參數:--bip=172.33.68.1/24 --ip-masq=true --mtu=1500。上述參數 flannel 啟動時運行的腳本生成的,通過環境變量傳遞過來的。
我們查看下 node1 宿主機上的網絡接口:
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:00:57:32 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic eth0
valid_lft 85095sec preferred_lft 85095sec
inet6 fe80::5054:ff:fe00:5732/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:7b:0f:b1 brd ff:ff:ff:ff:ff:ff
inet 172.17.8.101/24 brd 172.17.8.255 scope global eth1
valid_lft forever preferred_lft forever
4: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:ef:25:06 brd ff:ff:ff:ff:ff:ff
inet 172.30.113.231/21 brd 172.30.119.255 scope global dynamic eth2
valid_lft 85096sec preferred_lft 85096sec
inet6 fe80::a00:27ff:feef:2506/64 scope link
valid_lft forever preferred_lft forever
5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:d0:ae:80:ea brd ff:ff:ff:ff:ff:ff
inet 172.33.68.1/24 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:d0ff:feae:80ea/64 scope link
valid_lft forever preferred_lft forever
7: veth295bef2@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP
link/ether 6a:72:d7:9f:29:19 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::6872:d7ff:fe9f:2919/64 scope link
valid_lft forever preferred_lft forever
我們分類來解釋下該虛擬機中的網絡接口。
- lo:回環網絡,127.0.0.1
- eth0:NAT 網絡,虛擬機創建時自動分配,僅可以在幾台虛擬機之間訪問
- eth1:bridge 網絡,使用 vagrant 分配給虛擬機的地址,虛擬機之間和本地電腦都可以訪問
- eth2:bridge 網絡,使用 DHCP 分配,用於訪問互聯網的網卡
- docker0:bridge 網絡,docker 默認使用的網卡,作為該節點上所有容器的虛擬交換機
- veth295bef2@if6:veth pair,連接 docker0 和 Pod 中的容器。veth pair 可以理解為使用網線連接好的兩個接口,把兩個端口放到兩個 namespace 中,那麼這兩個 namespace 就能打通。參考 linux 網絡虛擬化:network namespace 簡介。 我們再看下該節點的 docker 上有哪些網絡。
docker network ls
NETWORK ID NAME DRIVER SCOPE
940bb75e653b bridge bridge local
d94c046e105d host host local
2db7597fd546 none null local
再檢查下 bridge 網絡940bb75e653b的信息。
docker network inspect 940bb75e653b
[
{
"Name": "bridge",
"Id": "940bb75e653bfa10dab4cce8813c2b3ce17501e4e4935f7dc13805a61b732d2c",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.33.68.1/24",
"Gateway": "172.33.68.1"
}
]
},
"Internal": false,
"Containers": {
"944d4aa660e30e1be9a18d30c9dcfa3b0504d1e5dbd00f3004b76582f1c9a85b": {
"Name": "k8s_POD_coredns-5984fb8cbb-sjqv9_kube-system_c5a2e959-082a-11e8-b4cd-525400005732_0",
"EndpointID": "7397d7282e464fc4ec5756d6b328df889cdf46134dbbe3753517e175d3844a85",
"MacAddress": "02:42:ac:21:44:02",
"IPv4Address": "172.33.68.2/24",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}}
]
我們可以看到該網絡中的Config 與 docker 的啟動配置相符。
Node1 上運行的容器:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a37407a234dd docker.io/coredns/coredns@sha256:adf2e5b4504ef9ffa43f16010bd064273338759e92f6f616dd159115748799bc "/coredns -conf /etc/" About an hour ago Up About an hour k8s_coredns_coredns-5984fb8cbb-sjqv9_kube-system_c5a2e959-082a-11e8-b4cd-525400005732_0
944d4aa660e3 docker.io/openshift/origin-pod "/usr/bin/pod" About an hour ago Up About an hour k8s_POD_coredns-5984fb8cbb-sjqv9_kube-system_c5a2e959-082a-11e8-b4cd-525400005732_0
我們可以看到當前已經有 2 個容器在運行。
Node1 上的路由信息:
route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.2.2 0.0.0.0 UG 100 0 0 eth0
0.0.0.0 172.30.116.1 0.0.0.0 UG 101 0 0 eth2
10.0.2.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
172.17.8.0 0.0.0.0 255.255.255.0 U 100 0 0 eth1
172.30.112.0 0.0.0.0 255.255.248.0 U 100 0 0 eth2
172.33.68.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
172.33.96.0 172.30.118.65 255.255.255.0 UG 0 0 0 eth2
以上路由信息是由 flannel 添加的,當有新的節點加入到 Kubernetes 集群中後,每個節點上的路由表都將增加。
我們在 node 上來 traceroute 下 node3 上的 coredns-5984fb8cbb-tkfrc 容器,其 IP 地址是 172.33.96.3,看看其路由信息。
traceroute 172.33.96.3
traceroute to 172.33.96.3 (172.33.96.3), 30 hops max, 60 byte packets
1 172.30.118.65 (172.30.118.65) 0.518 ms 0.367 ms 0.398 ms
2 172.33.96.3 (172.33.96.3) 0.451 ms 0.352 ms 0.223 ms
我們看到路由直接經過 node3 的公網 IP 後就到達了 node3 節點上的 Pod。
Node1 的 iptables 信息:
iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
KUBE-FIREWALL all -- anywhere anywhere
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
Chain FORWARD (policy ACCEPT)
target prot opt source destination
KUBE-FORWARD all -- anywhere anywhere /* kubernetes forward rules */
DOCKER-ISOLATION all -- anywhere anywhere
DOCKER all -- anywhere anywhere
ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED
ACCEPT all -- anywhere anywhere
ACCEPT all -- anywhere anywhere
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
KUBE-FIREWALL all -- anywhere anywhere
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
Chain DOCKER (1 references)
target prot opt source destination
Chain DOCKER-ISOLATION (1 references)
target prot opt source destination
RETURN all -- anywhere anywhere
Chain KUBE-FIREWALL (2 references)
target prot opt source destination
DROP all -- anywhere anywhere /* kubernetes firewall for dropping marked packets */mark match 0x8000/0x8000
Chain KUBE-FORWARD (1 references)
target prot opt source destination
ACCEPT all -- anywhere anywhere /* kubernetes forwarding rules */mark match 0x4000/0x4000
ACCEPT all -- 10.254.0.0/16 anywhere /* kubernetes forwarding conntrack pod source rule */ctstate RELATED,ESTABLISHED
ACCEPT all -- anywhere 10.254.0.0/16 /* kubernetes forwarding conntrack pod destination rule */ctstate RELATED,ESTABLISHED
Chain KUBE-SERVICES (2 references)
target prot opt source destination
從上面的 iptables 中可以看到注入了很多 Kuberentes service 的規則。
非 Overlay 扁平網絡 Calico
概念
Calico 創建和管理一個扁平的三層網絡(不需要 overlay),每個容器會分配一個可路由的 IP。由於通信時不需要解包和封包,網絡性能損耗小,易於排查,且易於水平擴展。
小規模部署時可以通過 BGP client 直接互聯,大規模下可通過指定的 BGP Route Reflector 來完成,這樣保證所有的數據流量都是通過 IP 路由的方式完成互聯的。
Calico 基於 iptables 還提供了豐富而靈活的網絡 Policy,保證通過各個節點上的 ACL 來提供 Workload 的多租戶隔離、安全組以及其他可達性限制等功能。
Calico 架構
Calico 由以下組件組成,在部署 Calico 的時候部分組件是可選的。
- Calico API server
- Felix
- BIRD
- confd
- Dikastes
- CNI 插件
- 數據存儲插件
- IPAM 插件
- kube-controllers
- Typha
- calicoctl
雲編排器插件
Calico 的架構圖如下所示:
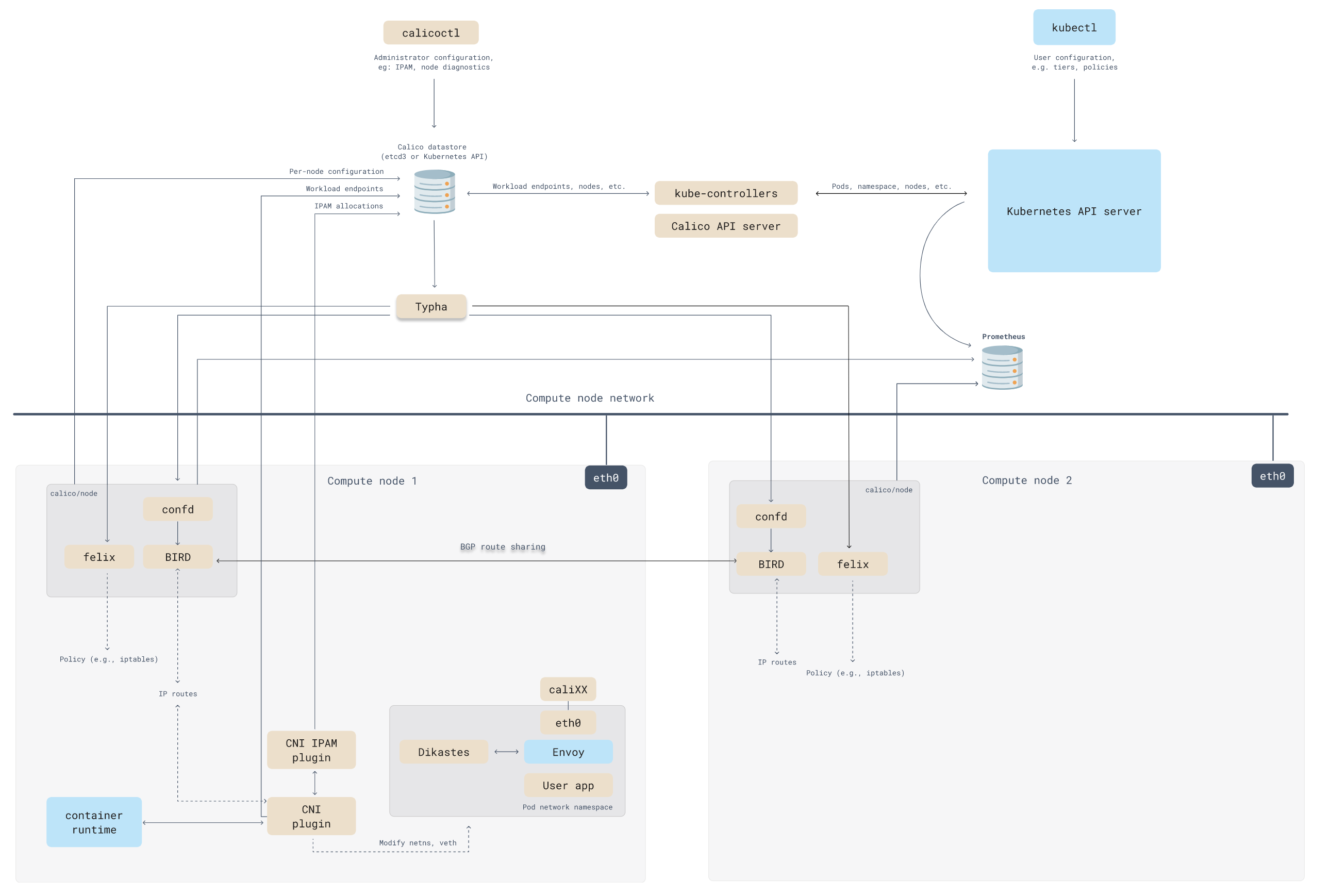
Calico API Server
可以使用 kubectl 直接管理 Calico。
Felix
Felix 以 agent 代理的形式在每台機器端點上運行。對路由和 ACL 以及主機編程,為該主機上的端點提供所需的連接。
根據具體的編排器環境,Felix 負責:
接口管理
將有關接口的信息編入內核,以便內核能夠正確處理來自該端點的流量。特別是,確保主機響應來自每個工作負載的 ARP 請求,提供主機的 MAC,並為它所管理的接口啟用 IP 轉發。它還監控接口,以確保編程在適當的時候應用。
路由編程
將其主機上的端點的路由編程到 Linux 內核的 FIB(轉發�信息庫)。這可以確保到達主機上的以這些端點為目的地的數據包被相應地轉發。
ACL 編程
在 Linux 內核中編程 ACL,以確保只有有效的流量可以在端點之間發送,並且端點不能規避 Calico 的安全措施。
狀態報告
提供網絡健康數據。特別是在配置其主機時報告錯誤和問題。這些數據被寫入數據存儲,以便對網絡的其他組件和運營商可見。
BIRD
BGP Internet Routing Daemon,簡稱 BIRD。從 Felix 獲取路由,並分發到網絡上的 BGP peer,用於主機間的路由。在每個 Felix 代理的節點上運行。
BGP 客戶端負責:
路由分配
當 Felix 將路由插入 Linux 內核的 FIB 時,BGP 客戶端將它們分配給部署中的其他節點。這確保了部署中的有效流量路由。
BGP 路由反射器的配置
BGP 路由反射器通常是為大型部署而配置的,而不是一個標準的 BGP 客戶端。BGP 路由反射器作為連接 BGP 客戶端的一個中心點。(標準 BGP 要求每個 BGP 客戶端在網狀拓撲結構中與其他每個 BGP 客戶端連接,這很難維護)。
為了實現冗余,你可以無縫部署多個 BGP 路由反射器。BGP 路由反射器只參與網絡的控制:沒有終端數據通過它們。當 Calico BGP 客戶端將其 FIB 中的路由通告給路由反射器時,路由反射器將這些路由通告給部署中的其他節點。
confd
開源的、輕量級的配置管理工具。監控 Calico 數據存儲對 BGP 配置和全局默認的日志變更,如 AS 號、日志級別和 IPAM 信息。
Confd 根據存儲中的數據更新,動態生成 BIRD 配置文件。當配置文件發生變化時,confd 會觸發 BIRD 加載新的文件。
Dikastes
執行 Istio 服務網格的網絡策略。作為 Istio Envoy 的一個 Sidecar 代理,在集群上運行。
Dikastes 是可選的。Calico 在 Linux 內核(使用 iptables,在三、四層)和三到七層使用 Envoy 的 Sidecar 代理 Dikastes 為工作負載執行網絡策略,對請求進行加密認證。使用多個執行點可以根據多個標準確定遠程端點的身份。即使工作負載 Pod 破壞,Envoy 代理被繞過,主機 Linux 內核的執行也能保護你的工作負載。
CNI 插件
為 Kubernetes 集群提供 Calico 網絡。
向 Kubernetes 展示該 API 的 Calico 二進制文件被稱為 CNI 插件,必須安裝在 Kubernetes 集群的每個節點上。Calico CNI 插件允許你為任何使用 CNI 網絡規範的編排調度器使用 Calico 網絡。
數據存儲插件
通過減少每個節點對數據存儲的影響來增加規模。它是 Calico CNI 的插件之一。
Kubernetes API datastore(kdd)
在 Calico 中使用 Kubernetes API 數據存儲(kdd)的優點是:
管理更簡單,因為不需要額外的數據存儲 使用 Kubernetes RBAC 來控制對 Calico 資源的訪問 使用 Kubernetes 審計日志來生成對 Calico 資源變化的審計日志 etcd
etcd 是一個一致的、高可用的分布式鍵值存儲,為 Calico 網絡提供數據存儲,並用於組件之間的通信。etcd 僅支持保護非集群主機(從 Calico v3.1 開始)。etcd 的優點是:
讓你在非 Kubernetes 平台上運行 Calico 分離 Kubernetes 和 Calico 資源之間的關注點,例如允許你獨立地擴展數據存儲。 讓你運行的 Calico 集群不僅僅包含一個 Kubernetes 集群,例如,讓帶有 Calico 主機保護的裸機服務器與 Kubernetes 集群互通;或者多個 Kubernetes 集群。 IPAM 插件 使用 Calico 的 IP 池資源來控制如何將 IP 地址分配給集群中的 pod。它是大多數 Calico 安裝所使用的默認插件。它是 Calico CNI 插件之一。
kube-controller
監控 Kubernetes 的 API,並根據集群狀態執行行動。
tigera/kube-controllers 容器包括以下控制器:
- Policy 控制器
- Namespace 控制器
- ServiceAccount 控制器
- WorkloadEndpoint 控制器
- Node 控制器
Typha
通過減少每個節點對數據存儲的影響來增加規模。作為數據存儲和 Felix 實例之間的一個守護程序運行。默認安裝,但沒有配置。
Typha 代表 Felix 和 confd 等所有客戶端維護一個單一的數據存儲連接。它緩存數據存儲的狀態,並覆制事件,以便它們可以被推廣到更多監聽器。因為一個 Typha 實例可以支持數百個 Felix 實例,可以將數據存儲的負載降低很多。由於 Typha 可以過濾掉與 Felix 無關的更新,它也減少了 Felix 的 CPU 使用。在一個大規模(100 多個節點)的 Kubernetes 集群中,這是至關重要的,因為 API 服務器產生的更新數量隨著節點數量的增加而增加。
calicoctl
Calicoctl 命令行作為二進制或容器需要單獨安裝,可以在任何可以通過網絡訪問 Calico 數據存儲的主機上使用。
雲編排器插件
將管理網絡的編排器 API 翻譯成 Calico 的數據模型和數據存儲。
對於雲供應商,Calico 為每個主要的雲編排平台提供了一個單獨的插件。這使得 Calico 能夠與編排器緊密結合,因此用戶可以使用他們的編排器工具來管理 Calico 網絡。當需要時,編排器插件會將 Calico 網絡的反饋信息提供給編排器。例如,提供關於 Felix liveness 的信息,並在網絡設置失敗時將特定端點標記為失敗。
基於 eBPF 的網絡 Cilium
Cilium 是一款開源軟件,也是 CNCF 的孵化項目,目前已有公司提供商業化支持,還有基於 Cilium 實現的服務網格解決方案。最初它僅是作為一個 Kubernetes 網絡組件。Cilium 在 1.7 版本後推出並開源了 Hubble,它是專門為網絡可視化設計,能夠利用 Cilium 提供的 eBPF 數據路徑,獲得對 Kubernetes 應用和服務的網絡流量的深度可視性。這些網絡流量信息可以對接 Hubble CLI、UI 工具,可以通過交互式的方式快速進行問題診斷。除了 Hubble 自身的監控工具,還可以對接主流的雲原生監控體系——Prometheus 和 Grafana,實現可擴展的監控策略。
Cilium 是什麽
Cilium 為基於 Kubernetes 的 Linux 容器管理平台上部署的服務,透明地提供服務間的網絡和 API 連接及安全。

Cilium 底層是基於 Linux 內核的新技術 eBPF,可以在 Linux 系統中動態注入強大的安全性、可視性和網絡控制邏輯。Cilium 基於 eBPF 提供了多集群路由、替代 kube-proxy 實現負載均衡、透明加密以及網絡和服務安全等諸多功能。除了提供傳統的網絡安全之外,eBPF 的靈活性還支持應用協議和 DNS 請求/響應安全。同時,Cilium 與 Envoy 緊密集成,提供了基於 Go 的擴展框架。因為 eBPF 運行在 Linux 內核中,所以應用所有 Cilium 功能,無需對應用程序代碼或容器配置進行任何更改。
基於微服務的應用程序分為小型獨立服務,這些服務使用 HTTP、gRPC、Kafka 等輕量級協議通過 API 相互通信。但是,現有的 Linux 網絡安全機制(例如 iptables)僅在網絡和傳輸層(即 IP 地址和端口)上運行,並且缺乏對微服務層的可視性。
Cilium 為 Linux 容器框架(如 Docker 和 Kubernetes) 帶來了 API 感知網絡安全過濾。使用名為 eBPF 的新 Linux 內核技術,Cilium 提供了一種基於容器 / 容器標識定義和實施網絡層和應用層安全策略的簡單而有效的方法。
eBPF
擴展的柏克萊封包過濾器(extented Berkeley Packet Filter,縮寫 eBPF),是 類 Unix 系統上 數據鏈路層 的一種原始接口,提供原始鏈路層 封包 的收發,除此之外,如果網卡驅動支持 洪泛 模式,那麽它可以讓網卡處於此種模式,這樣可以收到 網絡 上的所有包,不管他們的目的地是不是所在 主機。參考 維基百科 及BPF、eBPF、XDP 和 Bpfilter 的區別。
Hubble 是什麽
Hubble 是一個完全分布式的網絡和安全可觀測性平台。它建立在 Cilium 和 eBPF 之上,以完全透明的方式實現對服務的通信和行為以及網絡基礎設施的深度可視性(visibility)。
通過建立在 Cilium 之上,Hubble 可以利用 eBPF 實現可視性。依靠 eBPF,所有的可視性都是可編程的,並允許采用一種動態方法,最大限度地減少開銷,同時按照用戶的要求提供深入和詳細的可視性。Hubble 的創建和專門設計是為了最好地利用 eBPF 的能力。
特性 以下是 Cilium 的特性。
- 基於身份的安全性
- Cilium 可視性和安全策略基於容器編排系統的標識(例如,Kubernetes 中的 Label)。在編寫安全策略、審計和故障排查時,再也不用擔心網絡子網或容器 IP 地址了。
- 卓越的性能
- eBPF 利用 Linux 底層的強大能力,通過提供 Linux 內核的沙盒可編程性來實現數據路徑,從而提供卓越的性能。
- API 協議可視性 + 安全性
- 傳統防火墻僅根據 IP 地址和端口等網絡標頭查看和過濾數據包。Cilium 也可以這樣做,但也可以理解並過濾單個 HTTP、gRPC 和 Kafka 請求,這些請求將微服務拼接在一起。
- 專為擴展而設計
- Cilium 是為擴展而設計的,在部署新 pod 時不需要節點間交互,並且通過高度可擴展的鍵值存儲進行所有協調。
為什麽選擇 Cilium 和 Hubble?
現代數據中心應用程序的開發已經轉向面向服務的體系結構(SOA),通常稱為微服務,其中大型應用程序被分成小型獨立服務,這些服務使用 HTTP 等輕量級協議通過 API 相互通信。微服務應用程序往往是高度動態的,作為持續交付的一部分部署的滾動更新期間單個容器啟動或銷毀,應用程序擴展 / 縮小以適應負載變化。
這種向高度動態的微服務的轉變過程,給確保微服務之間的連接方面提出了挑戰和機遇。傳統的 Linux 網絡安全方法(例如 iptables)過濾 IP 地址和 TCP/UDP 端口,但 IP 地址經常在動態微服務環境中流失。容器的高度不穩定的生命周期導致這些方法難以與應用程序並排擴展,因為負載均衡表和訪問控制列表要不斷更新,可能增長成包含數十萬條規則。出於安全目的,協議端口(例如,用於 HTTP 流量的 TCP 端口 80)不能再用於區分應用流量,因為該端口用於跨服務的各種消息。
另一個挑戰是提供準確的可視性,因為傳統系統使用 IP 地址作為主要識別工具,其在微服務架構中的壽命可能才僅僅幾秒鐘,被大大縮短。
利用 Linux eBPF,Cilium 保留了透明地插入安全可視性 + 強制執行的能力,但這種方式基於服務 /pod/ 容器標識(與傳統系統中的 IP 地址識別相反),並且可以根據應用層進行過濾(例如 HTTP)。因此,通過將安全性與尋址分離,Cilium 不僅可以在高度動態的環境中應用安全策略,而且除了提供傳統的第 3 層和第 4 層分割之外,還可以通過在 HTTP 層運行來提供更強的安全隔離。
eBPF 的使用使得 Cilium 能夠以高度可擴展的方式實現以上功能,即使對於大規模環境也不例外。
功能概述
-
透明的保護 API
- 能夠保護現代應用程序協議,如 REST/HTTP、gRPC 和 Kafka。傳統防火墻在第 3 層和第 4 層運行,在特定端口上運行的協議��要麽完全受信任,要麽完全被阻止。Cilium 提供了過濾各個應用程序協議請求的功能,例如:
- 允許所有帶有方法 GET 和路徑 /public/.* 的 HTTP 請求。拒絕所有其他請求。
- 允許 service1 在 Kafka topic 上生成 topic1,service2 消費 topic1。拒絕所有其他 Kafka 消息。
- 要求 HTTP 標頭 X-Token: [0-9]+ 出現在所有 REST 調用中。
- 能夠保護現代應用程序協議,如 REST/HTTP、gRPC 和 Kafka。傳統防火墻在第 3 層和第 4 層運行,在特定端口上運行的協議��要麽完全受信任,要麽完全被阻止。Cilium 提供了過濾各個應用程序協議請求的功能,例如:
-
基於身份來保護服務間通信
- 現代分布式應用程序依賴於諸如容器之類的技術來促進敏捷性並按需擴展。這將導致在短時間內啟動大量應用容器。典型的容器防火墻通過過濾源 IP 地址和目標端口來保護工作負載。這就要求不論在集群中的哪個位置啟動容器時都要操作所有服務器上的防火墻。
- 為了避免受到規模限制,Cilium 為共享相同安全策略的應用程序容器組分配安全標識。然後,該標識與應用程序容器發出的所有網絡數據包相關聯,從而允許驗證接收節點處的身份。使用鍵值存儲執行安全身份管理。
-
安全訪問外部服務
- 基於標簽的安全性是集群內部訪問控制的首選工具。為了保護對外部服務的訪問,支持入口(ingress)和出口(egress)的傳統基於 CIDR 的安全策略。這允許限制對應用程序容器的訪問以及對特定 IP 範圍的訪問。
-
簡單網絡
- 一個簡單的扁平第 3 層網絡能夠跨越多個集群連接所有應用程序容器。使用主機範圍分配器可以簡化 IP 分配。這意味著每個主機可以在主機之間沒有任何協調的情況下分配 IP。
支持以下多節點網絡模型:
- Overlay:基於封裝的虛擬網絡產生所有主機。目前 VXLAN 和 Geneve 已經完成,但可以啟用 Linux 支持的所有封裝格式。
- 何時使用此模式�:此模式具有最小的基礎架構和集成要求。它幾乎適用於任何網絡基礎架構,唯一的要求是主機之間可以通過 IP 連接。
- 本機路由:使用 Linux 主機的常規路由表。網絡必須能夠路由應用程序容器的 IP 地址。
- 何時使用此模式:此模式適用於高級用戶,需要了解底層網絡基礎結構。此模式適用於:
- 本地 IPv6 網絡
- 與雲網絡路由器配合使用
- 如果您已經在運行路由守護進程
- 何時使用此模式:此模式適用於高級用戶,需要了解底層網絡基礎結構。此模式適用於:
負載均衡
應用程序容器和外部服務之間的流量的分布式負載均衡。負載均衡使用 eBPF 實現,允許幾乎無限的規模,並且如果未在源主機上執行負載均衡操作,則支持直接服務器返回(DSR)。
監控和故障排除
可視性和故障排查是任何分布式系統運行的基礎。雖然我們喜歡用 tcpdump 和 ping,它們很好用,但我們努力為故障排除提供更好的工具。包括以下工具:
使用元數據進行事件監控:當數據包被丟棄時,該工具不僅僅報告數據包的源 IP 和目標 IP,該工具還提供發送方和接收方的完整標簽信息等。 策略決策跟蹤:為什麽丟棄數據包或拒絕請求。策略跟蹤框架允許跟蹤運行工作負載和基於任意標簽定義的策略決策過程。 通過 Prometheus 導出指標:通過 Prometheus 導出關鍵指標,以便與現有儀表板集成。
集成
- 網絡插件集成:CNI、libnetwork
- 容器運行時:containerd
- Kubernetes:NetworkPolicy、Label、Ingress、Service
- 日志記錄:syslog、fluentd
概念
Cilium 要求 Linux kernel 版本在 4.8.0 以上,Cilium 官方建議 kernel 版本至少在 4.9.17 以上,高版本的 Ubuntu 發行版中 Linux 內核版本一般在 4.12 以上,如使用 CentOS7 需要升級內核才能運行 Cilium。
KV 存儲數據庫用存儲以下狀態:
- 策略身份,Label 列表 ↔ 服務身份標識
- 全局的服務 ID,與 VIP 相關聯(可選)
- 封裝的 VTEP(Vxlan Tunnel End Point)映射(可選) 為了簡單起見,Cilium 一般跟容器編排調度器使用同一個 KV 存儲數據庫,例如在 Kubernetes 中使用 etcd 存儲。
組成
下圖是 Cilium 的組件示意圖,Cilium 是位於 Linux kernel 與容器編排系統的中間層。向上可以為容器配置網絡,向下可以向 Linux 內核生成 BPF 程序來控制容器的安全性和轉發行為。
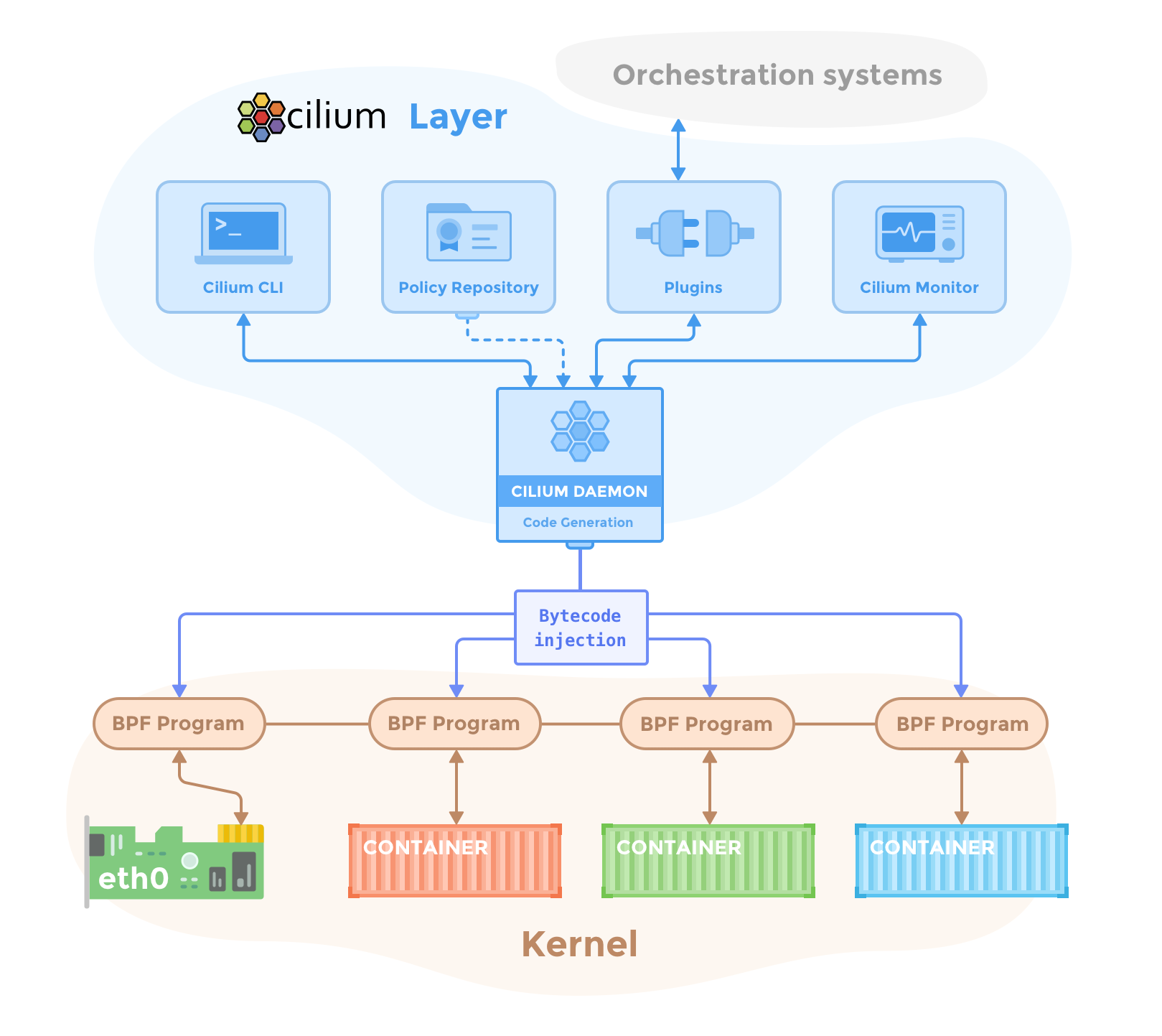
管理員通過 Cilium CLI 配置策略信息,這些策略信息將存儲在 KV 數據庫里,Cilium 使用插件(如 CNI)與容器編排調度系統交互,來實現容器間的聯網和容器分配 IP 地址分配,同時 Cilium 還可以獲得容器的各種元數據和流量信息,提供監控 API。
Cilium Agent
Cilium Agent 作為守護進程運行在每個節點上,與容器運行時如 Docker,和容器編排系統交互如 Kubernetes。通常是使用插件的形式(如 Docker plugin)或遵從容器編排標準定義的網絡接口(如 CNI)。
Cilium Agent 的功能有:
- 暴露 API 給運維和安全團隊,可以配置容器間的通信策略。還可以通過這些 API 獲取網絡監控數據。
- 收集容器的元數據,例如 Pod 的 Label,可用於 Cilium 安全策略里的 Endpoint 識別,這個跟 Kubernetes 中的 service 里的 Endpoint 類似。
-
- 與容器管理平台的網絡插件交互,實現 IPAM 的功能,用於給容器分配 IP 地址,該功能與 flannel、calico 網絡插件類似。 將其有關容器標識和地址的知識與已配置的安全性和可視性策略相結合,生成高效的 BPF 程序,用於控制容器的網絡轉發和安全行為。
- 使用 clang/LLVM 將 BPF 程序編譯為字節碼,在容器的虛擬以太網設備中的所有數據包上執行,並將它們傳遞給 Linux 內核。
命令行工具
Cilium 提供了管理命令行管理工具,可以與 Cilium Agent API 交互。cilium 命令使用方式如下。
Usage:
cilium [command]
Available Commands:
bpf 直接訪問本地 BPF map
cleanup 重置 agent 狀態
completion bash 自動補全
config Cilium 配置選項
debuginfo 從 agent 請求可用的調試信息
endpoint 管理 endpoint
identity 管理安全身份
kvstore 直接訪問 kvstore
map 訪問 BPF map
monitor 顯示 BPF 程序事件
node 管理集群節點
policy 管理安全策略
prefilter 管理 XDP CIDR filter
service 管理 service & loadbalancer
status 顯示 daemon 的狀態
version 打印版本信息
策略控制示例
使用 docker-compose 安裝測試,需要先用 vagrant 啟動虛擬機,使用的是 Ubuntu-17.10 的 vagrant box。在下面的示例中,Cilium 是使用 docker network plugin 的方式部署的。Cilium 的一項主要功能——為容器創建網絡,使用 docker inspect 來查詢使用 Cilium 網絡的容器配置,可以看到 Cilium 創建的容器網絡示例如下。
"Networks": {
"cilium-net": {
"IPAMConfig": null,
"Links": null,
"Aliases": [
"a08e52d13a38"
],
"NetworkID": "c4cc3ac444f3c494beb1355e4a9c4bc474d9a84288ceb2030513e8406cdf4e9b",
"EndpointID": "2e3e4486525c20fc516d0a9d1c52f84edf9a000f3068803780e23b4c6a1ca3ed",
"Gateway": "",
"IPAddress": "10.15.125.240",
"IPPrefixLen": 32,
"IPv6Gateway": "f00d::a0f:0:0:1",
"GlobalIPv6Address": "f00d::a0f:0:0:ed50",
"GlobalIPv6PrefixLen": 128,
"MacAddress": "",
"DriverOpts": null
}
}
- NetworkID:每個網絡平面的唯一標識
- EndpointID:每個容器/Pod 的在網絡中的唯一標識 在 docker-compose 安裝方式的快速開始指南中,演示了如何使用 Label 來選擇容器,從而限制兩個容器(應用)之間的流量訪問權限的。
策略使用 JSON 格式配置,例如官方示例使用 Cilium 直接在 L3/L4 層管理容器間訪問策略的方式。例如下面的策略配置具有 id=app2 標簽的容器可以使用 TCP 協議、80 端口訪問具有標簽 id=app1 標簽的容器。
[{
"labels": [{"key": "name", "value": "l3-rule"}],
"endpointSelector": {"matchLabels":{"id":"app1"}},
"ingress": [{
"fromEndpoints": [
{"matchLabels":{"id":"app2"}}
],
"toPorts": [{
"ports": [{"port": "80", "protocol": "TCP"}]
}]
}]
}]
將該配置保存成 JSON 文件,在使用 cilium policy import 命令即可應用到 Cilium 網絡中。
Cilium 網絡配置策略
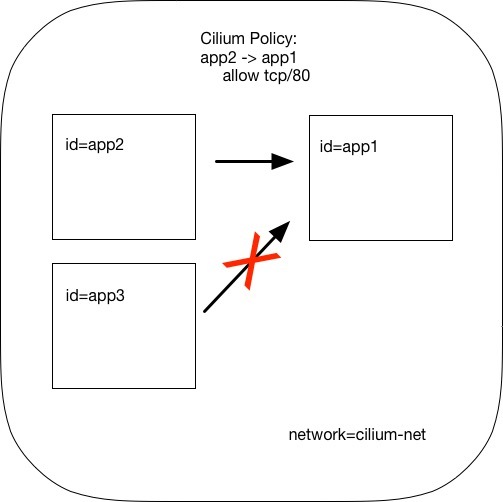
如圖所示,此時 id 標簽為其他值的容器就無法訪問 id=app1 容器,策略配置中的 toPorts 中還可以配置 HTTP method 和 path,實現更細粒度的訪問策略控制。